2026年7月2日
なぜ運用テストが重要なのか ― リリース後トラブルを防ぐために
システムテスト 2026年5月21日
#運用テスト
トラブルって、
起きてから対処するものだよね
起きてから対処するものだよね
![]()
事前に防げるものも結構あるよ
じゃあリリース後は毎朝お祈りしよう
![]()
神頼みより事前確認。
リリース後トラブルを防ぐのが運用テストだよ
リリース後トラブルを防ぐのが運用テストだよ
“テスト済み”のはずのシステムで、なぜリリース後トラブルが起きるのか
「要件定義どおりに機能は実装した。単体テストも結合テストも完了している。それでも、リリース当日にシステムが停止した。」
プロジェクトマネージャー(PM)にとって、これは特定の現場に限った例外的な出来事ではありません。IPA(情報処理推進機構)が公開しているシステム障害事例を見ても、大手金融機関や人気サービスにおいて、リリース直後に障害が発生するケースが報告されています。
ではなぜ、十分なテストを経たはずのシステムで、本番稼働後にトラブルが発生してしまうのでしょうか。
その一因は、「正しく作られているか」を確かめるテストと、「現場で問題なく使い続けられるか」を確かめるテストの間にある、検証観点のズレにあります。
本コラムでは、この観点のズレに着目し、リリース後トラブルを防ぐために、なぜ運用テストが重要なのかを解説します。
運用テストとは何か
運用テストとは、システムが本番環境に極めて近い環境において、実際の運用手順どおりに安定して稼働し続けられるかを検証する、リリース前に行う最終確認工程です。
開発工程の終盤で実施されるシステムテストが、仕様どおりに機能が動作するか(=機能の正しさ)を確認する工程であるのに対し、運用テストは、リリース後の日常業務に耐えられるか障害やトラブルが起きても立て直せるかといった、「運用の持続可能性」を確認することに主眼を置きます。

運用テストは、システムを単なる「動くプログラム」から、ビジネスを支え続ける「信頼できるサービス」へと仕上げる工程だと言えます。
受入テストとの違い
運用テストと混同されやすい工程に、受入テストがあります。どちらも本番稼働直前に実施されますが、重視する視点と目的が明確に異なります。
ユーザー視点で「業務が成立するか」を確認する受入テストに対し、運用・管理者視点の運用テストは「安定稼働に向けた準備(障害復旧や負荷耐性)」の検証を目的とします。
本番で顕在化しやすい3つの見落としポイント
【機能面】正常系中心のテストが招くイレギュラーな不具合
開発者や社内テスターによるテストには、どうしても避けがたい心理的な偏りが存在します。その一つが、「想定どおりに動くはず」という前提に寄った検証です。
システムを熟知している開発者ほど、操作時にも自然と正しい手順を選択してしまいます。
その結果、次のような前提が無意識のうちに置かれがちです。
「ここで戻るボタンを押すことはないだろう」
「1秒間に何度もボタンを連打することはないだろう」
「絵文字や特殊記号を入力することはないだろう」
こうした前提は、開発やテストを効率的に進めるうえでは有効です。
一方で、想定外の操作や例外的な挙動を検証対象から外してしまうというリスクも含んでいます。
しかし実際のユーザーは、必ずしも開発者の想定どおりに行動するわけではありません。操作に迷い、戻り、やり直し、ときには開発者の想像を超える使い方をすることもあります。

探索的テストというアプローチ
品質保証の現場では、あえてこの「想定から外れた使われ方」に焦点を当てる探索的テストが行われます。
探索的テストでは、次のアプローチによって、仕様書だけでは見つからない潜在的な不具合を洗い出します。
- 操作を意図的に崩す
- 異常値や境界条件を積極的に試す
- ユーザー視点で自由にシステムを触る
運用テストにおいて重要なのは、正しく使われた場合だけでなく、想定どおりに使われなかった場合でも業務が破綻しないかを確認することなのです。
「探索的テスト」についてはこちらの記事をご覧ください。
【環境面】「テスト環境では問題なかった」が通用しない理由
「自分のPCでは動いていた」、「ステージング環境までは問題なかった」
これらは、障害発生後の振り返りで頻繁に聞かれる言葉です。
検証環境と本番環境の間には、本質的な差異が存在します。この差異を十分に考慮しないままリリースすることが、本番トラブルの大きな要因となります。
テスト環境と本番環境で異なる「データ量」と「データ品質」
検証環境では、数十件から数百件程度の整備されたテストデータを用いて確認することが一般的です。
一方、本番環境には、数百万件規模のデータが存在し、長年の運用によって次のような状態が混在しています。
- 不整合を含むデータ
- 欠損値(Null値)
- 想定外の文字種や形式
- 移行時に取り込まれた例外データ
この違いは、処理性能に大きな影響を与えます。たとえば、検証環境では0.1秒で完了していた処理が、本番環境では30秒以上かかり、タイムアウトや処理失敗を引き起こすことがあります。
こうした問題の多くは、非機能要件(特にパフォーマンス)の検証不足によって顕在化します。
機能テストでは見落とされる、クラウド設定起因のリスク
AWSやAzureなどのクラウド利用が一般化した現在、本番トラブルの原因は、プログラムの不具合ではなく設定ミスであるケースが増えています。
ストレージの権限設定やネットワークの公開範囲といった構成上の不備は、機能テストだけでは見落とされがちです。そのため、インフラやセキュリティ設定を含めた、本番環境前提の検証が不可欠となっています。
これらの問題は、画面操作や業務フローを確認する機能テストでは発見できません。
インフラ構成やセキュリティ設定を含め、本番環境を前提として検証することが不可欠です。
【運用面】障害発生時に業務を止めないための準備はできているか
運用テストの目的は、システムが正常に動作することを確認するだけではありません。
より重要なのは、万が一トラブルが発生した場合でも、業務を継続できるかを確認することです。
データ移行は、特に留意すべき重要工程の一つ
新システムへの切り替えにおいて、失敗時の影響が最も大きく、やり直しが難しい工程がデータ移行です。
過去には、金融機関や小売業においてデータ移行の不備により、顧客データの消失、二重請求や残高不整合といった問題が発生し、結果として大きな金銭的・社会的損失につながった事例も報告されています。
そのため、本番データ、またはそれに準ずるデータを用いた移行リハーサル(移行テスト)を実施し、以下の点を事前に検証することは、不可欠なリスク管理です。
- 想定したタイムスケジュール内に完了するか
- 移行後のデータ内容が正しいか
- 失敗時に切り戻しが可能か
「回避策」は、訓練して初めて機能する
システム障害が発生した際、「手作業で対応する」「電話や紙で業務を継続する」といった運用上の回避策が用意されているケースは少なくありません。
しかし、実際に訓練されていない回避策は、本番では機能しないという点が、しばしば見落とされます。
運用テスト期間中に、あえてシステム停止を想定した訓練を行い、現場担当者がマニュアルどおりに動けるか、連絡・判断・切り替えが滞りなく行われるかを確認することで、リリース後の混乱や現場のパニックを大きく抑えることができます。
運用テストによってリスクを可視化する方法
リリース後のトラブルの多くは、プログラムミスではなく、「想定外の操作」や「本番環境との差異」、「障害対応の準備不足」といった、開発と運用の境界に潜むリスクが原因です。
これらは開発チーム自身では気づきにくく、本番で初めて表面化しやすいという特徴があります。
コストの「1:10:100の法則」が示す現実
ソフトウェア品質の分野には、「1:10:100の法則」と呼ばれる経験則があります。
- 開発初期に検出できた不具合:コスト「1」
- テスト工程で発覚した不具合:コスト「10」
- リリース後に発覚した不具合:コスト「100」
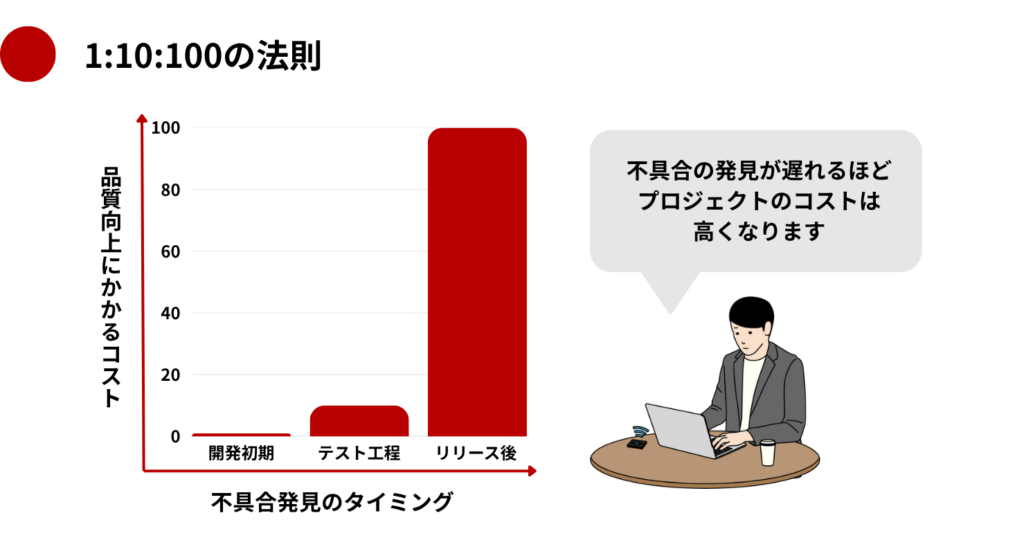
この差が生まれる理由は、リリース後の対応には単なる改修費用だけでなく、次のような目に見えにくい損失が含まれるためです。
- サービス停止による機会損失
- 顧客対応・謝罪対応に伴う人的コスト
- ブランド価値の毀損や信頼低下
しかし、これらを、納期・予算・人員制約を抱えた開発チームだけで網羅的にカバーするのは、現実的とは言えません。そのため多くの企業が、第三者検証(テスト専門会社)を品質確保のための「最後の防波堤」として活用しています。

まとめ
運用テストは、リリース判断の精度を高めるうえで有効な手段です。ただし、運用テストだけですべてのリスクを網羅できるわけではありません。
想定外のユーザー操作や本番特有の環境差異、障害発生時の対応可否といった課題は、機能テスト、性能テスト、セキュリティ診断、運用・移行リハーサルなど、複数のテストを組み合わせることで初めて立体的に把握できます。
特に大規模・高負荷なシステムでは、単一のテスト結果に基づく判断は大きなリスクを伴います。
一方で、こうした多角的な検証を、限られた人員やスケジュールの中で自社だけで正確に実施するのは容易ではありません。
株式会社GENZでは、経験豊富なテストエンジニアが、受け入れテストを含むソフトウェア品質テストを中心に、ITに関するさまざまな課題に対応しています。運用テストや第三者検証に関するご相談は、お気軽にお問い合わせください。
この記事を書いた人
GENZ マーケティンググループ TM
ソフトウェアテスト・品質保証の専門集団「GENZ」のマーケティングチームです。
企業文化や最新トピック、システムテストのノウハウ、品質改善の事例など、開発・テスト現場に役立つ情報を発信中。
「品質×マーケティング」で、読者とGENZの架け橋となるコンテンツをお届けします。